計算量とは?【アルゴリズムに必須】
※ このサイトはアフィリエイト広告(Amazonアソシエイト含む)を掲載しています。
計算量とは、アルゴリズムが解を見つけるのに必要なリソース(時間やメモリ)を数学的に分析したものです。考えたアルゴリズムが十分に効率的であるかを判断するために、アルゴリズムの計算量を見積もることが必要になります。
目次
計算量の表現
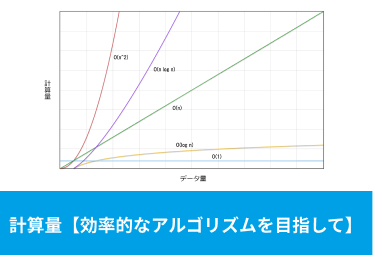
Big O記法
Big O記法とは、アルゴリズムの計算量を表現するために用いられます。この記法は、入力サイズが増えるにつれて、アルゴリズムの実行時間や必要なメモリ量がどのように変化するかを示します。
計算量は、通常「何に比例するか」で考えます。例えば、以下のようなコードを考えてみましょう。
def cubic_algorithm(N):
count = 0
for i in range(N):
for j in range(N):
for k in range(N):
count += 1
return countこちらのコードでは、N(入力サイズ)回のループが3重になっているので、実行時間はN3に比例します。N3に比例するものをO(N3)と書きます。
N3に比例しているかを具体例を通じて確認してみましょう。
- 入力サイズ:1 → ステップ数:1
- 入力サイズ:2 → ステップ数:8
- 入力サイズ:3 → ステップ数:27
- 入力サイズ:4 → ステップ数:64
このように、N(入力サイズ)の3乗に比例して増加していることがわかります。
※ Big O記法は最悪ケースのパフォーマンスを示します。
Big O記法の主な形式は
- O(1):入力サイズに関係なく、アルゴリズムの実行時間は定数
- O(logN):入力サイズが倍になっても、追加のステップ数は一定量しか増えない
- O(N):入力サイズが倍になると、ステップ数も倍になる
- O(NlogN):典型的には、良好な性能を持つソートアルゴリズムに見られる
- O(N2):入力サイズが倍になると、ステップ数は約4倍
- O(2N):入力サイズが増えると、ステップ数は指数的に増える
- O(N!):アルゴリズムのステップ数が入力サイズの階乗に比例
この中でも特に、O(N2)、O(2N)、O(N!)になるようなアルゴリズムは避けた方が良いです。
計算量の種類
時間計算量(Time Complexity)
時間計算量は、アルゴリズムが問題を解くのに必要なステップ数を示します。
一般的に入力サイズNの関数として表されます。
空間計算量(Space Complexity)
空間計算量は、アルゴリズムが問題を解くために必要なメモリの使用量を示します。
一般的に入力サイズNの関数として表されます。
計算量の例
ここまで計算量の定義を学んできましたが、定義を学んだだけではイメージを掴みにくいので、実際の例を見ながら計算量の理解を深めていきましょう。
時間計算量:O(1)
def get_first_element(arr: List[int]):
return arr[0]この関数では、入力されたリストの最初の要素を取得します。
取得する操作は、リストの長さ(入力サイズ)に関係なく常に一定の時間で実行されます。そのため、時間計算量はO(1)です。
空間計算量はO(1)です。入力サイズに比例して新たにメモリを確保することはないため空間計算量は定数です。
時間計算量:O(N)
def calculate_sum(arr: List[int]):
total = 0
for num in arr:
total += num
return total配列の要素数Nに比例して、forループが1回ずつ処理を行います。各ループ内の操作(加算 total += 1)は定数時間O(1)です。
そのため、時間計算量はO(N)です。
空間計算量はO(1)です。入力サイズに比例して新たにメモリを確保することはないため空間計算量は定数です。
時間計算量:O(logN)
def binary_search(arr: List[int], target: int):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2 # 中間インデックスを計算
if arr[mid] == target:
return mid # ターゲットが見つかった場合
elif arr[mid] < target:
left = mid + 1 # ターゲットが右側にある場合
else:
right = mid - 1 # ターゲットが左側にある場合
return -1 # ターゲットが見つからない場合1.ソート済み配列arrを入力として受け取り、ターゲット値targetを探索します。
2.配列の中央の要素を確認し、ターゲット値がその左側または右側にあるがで探索範囲を半分にします。
3.探索範囲が空になるまでこの手順を繰り返します。
このアルゴリズムでは、探索範囲を毎回半分にするため、時間計算量はO(logN)です。
なぜlogNに比例するのか?
ここでは、時間計算量がO(logN)になるのかが直感的にわかりにくいので、解説します。(わかる方は、飛ばして先に進んでください。)
このアルゴリズムでは、上記の説明のように探索範囲を半分に分割しながら進めます。
探索範囲の大きさの変化は以下のようになります。
- 初回:N
- 1回目の比較後:N/2
- 2回目の比較後:N/4
- ︙
- k回目の比較後:N/2k
探索が終了する条件は、探索範囲が1以下になる時です。
k回目で探索が終了する場合で考えます。
終了条件を数式で表すと:
N/2k <= 1
両辺に2kをかけて整理すると:
N <= 2k
両辺の対数(底2)を取ります:
log2N <= k
つまり、探索が終了するまでの比較回数kは次のようになります:
k ≒ log2N
したがって、アルゴリズムの最大比較回数がlog2Nに比例するため、時間計算量はO(logN)となります。
空間計算量はO(1)です。入力サイズに比例して新たにメモリを確保することはないため空間計算量は定数です。
ちなみに、こちらのアルゴリズムは二分探索と言います。
空間計算量:O(N)
def cumulative_sum(arr: List[int]):
result = []
total = 0
for x in arr:
total += x
result.append(total)
return result新しい配列resultを作成し、入力配列の各要素に対する累積和を格納します。
その結果、配列のサイズが入力サイズと同じになるため、空間計算量はO(N)です。
空間計算量:O(N2)
def create_matrix(n: int):
return [[0 for _ in range(n)] for _ in range(n)]この関数では、n×nの2次元配列を作成します。
行列全体の要素数はn×nであるため、空間計算量はO(N2)です。
まとめ
今回は、アルゴリズムの効率を考える上で必須の計算量について解説しました。今後は考えたアルゴリズムの計算量も意識しながら実装するようにしましょう。
また、この記事で紹介しきれなかった計算量は各アルゴリズムの解説記事にのせているので、ぜひ参考にしてみてください。
このブログだけでもデータ構造とアルゴリズムを網羅的に学べますが、本で学びたい方にはこちらがおすすめです!
おすすめ記事